
Liberty Two-Four is now Air Force One
In the movie Air Force One, you might remember the scene where Harrison forward is bobbing around in the sky. His plane lost control and crashed into the ocean as another air force plane, Liberty 24 pulls him in.
As he boards the plane, we hear the pilot radio in to eagerly awaiting Washington, “Standby….Liberty 2–4 is changing call signs, Liberty 2–4 is now Air Force One”
Of course we all know the majestic blue and white plane only takes on the name Air Force One when the president is on board, otherwise it is known as SAM 26000 (Special Air Mission).
I’ve mentioned earlier how important a name can be framing how one things about a problem. Today’s story talks about how we took this concept of a name changing to help us solve a serious engineering problem.
When you use a website and click a link, you expect that website to do something right away. However what if that link is something like Facebook’s “Download all of my Data.” User expectation for something like that is some process will run in the background, and after some time you’ll be emailed the results.
The technique of running a process in the background is certainly something you could take for granted, but it’s the kind of thing that keeps websites alive when done right.
When we first rolled out background tasks and reports in 2012, we used a very naive method. We would run reports in the same thread pool as the main web request, which meant as we hit high web traffic we’d end up with reports simply not running.
In fact by early 2014 we started getting support tickets claiming reports simply weren’t running. Turns out those customers were right, about 30% of the time when you’d ask OpenWater (then called awardsCMS) to run a report you’d come back with nothing. Sometimes you’d only find out after hours of waiting that there would be nothing coming.
Around that time we scrambled for something that would help and Zack came across a tool called Hangfire. Hangfire intelligently ran jobs in the background and would retry them in case something went wrong. After a few months we had Hangfire implemented and without much fanfare complaints about jobs failing dwindled down to about 0.
2014 was also noteworthy because it was the year we re-branded from awardsCMS to OpenWater. This name that I was originally against, ended up being the backbone of how we build systems at the company.
The first tool we built in the OpenWater era was SONAR. SONAR is undersea technology that sends audio pings to receive data about objects. We were using a variety of software systems to keep our business going. Besides the platform itself, we needed customer support software (Zendesk, then, Intercom now), sales tracking software (Salesforce), and billing software (Xero). SONAR was the tool we developed that constantly pinged all of these systems and allowed for data sharing between then. For example if a sales person wanted to know which support rep was working on the customer they signed, SONAR would come through and link that information for them.

If you have been to Seaworld or seen Blackfish you know all about killer whales. In sales terminology, whales are the “big accounts” so for us, we needed a cost effective way to find out who these people might be and how we could reach out to them. Our sales research tool was aptly named Orca.

In 1990 spy thriller, The Hunt for Red October, a Russian commander piloting a top secret high tech submarine defects and transfers this technology to the U.S. When we needed a tool for our competitor research tool, Red October quickly became our code name for this project.
There are only two hard things in Computer Science: cache invalidation and naming things.
— PHIL KARLTON
I’ll leave the article for cache invalidation for another day, but Phil Karlton, a master of design and computer architecture was spot on when he said that naming was an insane challenge. Besides computer science, the social scientists at Freakonomics taught us how a person’s name can change their whole outlook and lot in life.
After we came up with all of these fun names for our internal tools we set out a rule — we can’t start on a new project until we come up with an appropriate naval related name for it. We realized that if we had the right name for something, we would build it following the appropriate metaphor. 90% of computer science is thinking, so if we spend a lot of time thinking about a name it also means we spend a lot of time thinking about why something has a name.
Our software operates in the public cloud, we mostly rely on Microsoft Azure for our computational workloads. I mentioned earlier how the backend of our platform runs on Hangfire, the front-end is powered by web servers running on Microsoft Azure App Service. When our servers are under extremely high load, some of our web servers would crap out. Since we always run multiple copies of our software, if one server was acting funny we would get reports along the lines of “the page seems to take forever to load, then its fast, then its slow again, very bizarre.”
Under high load, if a server starts acting up, Azure App Service is supposed to take the server out of rotation, restart it and bring it back online. This was the earlier days of the cloud though, so in some cases a node would get stuck — it would be dead, but not yet be taken out of rotation. This created the phenomenon described above. The only solution at the time was to stop the entire service and start it, doing so would guarantee us a fresh batch of new servers. The problem is under high load if we stopped the service it would mean a full 10–15 minute outage when several thousand people are using the site, it was better for us to hang on with intermittent complaints than an avalanche of anger hitting our support lines.

In the military a Hull Swap is an exercise where the crew of one ship finds its way onto another ship. Often the vessel they are on is need of major servicing and needs a new crew to do that work. To stay ready for operations they need to get onto a new craft.
Hull Swap was the perfect name for our tool to help us fix the stuck node situation. We realized if we could transfer all traffic from the impacted environment, restarted that environment, and then sent traffic back once all was fixed we could get around the stuck node issue without any downtime.
We are now in 2019 and Azure App Service has come a long way. The idea of stuck node isn’t something we really have to worry about anymore. The technology we built for Hull Swap however lives on with a new purpose.
From 2012 to early 2018 just about every morning my routine was as follows:
- Wake up and check for new updates that are ready to be rolled out (e.g. bug fixes)
- Review the code and then copy it to App Service 1
- I’d then shave, roughly a 6 minute process, and then begin copying of the code to App Service 2
- I’d hop in the shower, roughly 10 minutes, just in time for the copying to be finished
- I’d then finish updating our platforms and doing some quick checks
Major releases were even more hectic, I would wake up around 2 to 4 AM and begin a checklist that could take anywhere from 2 to 10 hours. Often I would have to give up a Friday or Saturday night (or both) each time we rolled out an update. Not the best way to spend my late 20s, but I was determined not to let this process enter my 30s.
Using the technology of Hull Swap + a few modifications we implemented our latest tool. After my morning code review I now click a single button and Tugboat begins its journey taking our code from the staging environment to our live environment. Tugboat then performs a Hull Swap with our live environment. With no downtime we get updates sent to the platform every morning. Major updates can now be done during slow periods (e.g. Sunday morning), instead of the middle of the night.

With Tugboat in full operation and Azure App Service working really well, I could start to add back normalcy to my morning routine. One of the first changes I made was to make sure I hit the gym in the mornings. As I could clock in each month of stability and perfect up-time I started feeling comfortable working out without my phone.
Big mistake.
On a Thursday morning during February, I return to my locker. 2 missed calls from Zack. I load up slack, I see our support chat room blowing up. This can’t be good.
I get Zack on the phone:
- Zack: Hey man…none of our background jobs are processing
- Kunal: What do you see in Hangfire?
- Zack: Hold on let me look….
- Zack: Oh s*(@!. 4,000 jobs and its increasing as we speak
It looks like that stuck node problem had a cousin and that cousin didn’t like Hangfire very much. The way we fixed this was a similar process to the stuck node problem, restart the servers and wait it out.
This problem happened a few more times during our busy season and then hid away. The best we could do was detect when it was about to happen and then implement the manual process. February ended and we went back to our smoother months. March, April, May, June, all went by fine. By the time the summer hit, we forgot we even had this problem.
Then seemingly out of nowhere the detector lit up in early September. Fortunately we were at hand to quickly solve it. Then again it happened, this time at around 3 AM on a Wednesday. We were not so lucky, it wasn’t until around 7 AM until one of us noticed and fixed the problem. Our European customers were not too happy.
We had to do something about this. We learned that the people who maintain Hangfire rolled out an update for this situation. It would take us about 3 months to implement the fixes in OpenWater, so what would we do in the meantime?
We got to thinking — of course we started with the name. We started talking through our current solution. I can’t remember which one of us said what, but here are some of our notes
- “Hangfire really needs help when its under heavy load”
- “Yea, its like when it is about to die it needs to make a call for help”
- “Dude, Save Our Sever, F*&!@ SOS”
- “OMG, SOS! Totally perfect name”
- “But who would save it, we’ll be asleep”
- “Dude… Tugboat”
- “Dude…”
We realized our emergency procedures altered Tugboat to act like Hangfire. That would buy us a precious 5 minutes of processing time while the main Hangfire servers were restarting.
Like Liberty 24, we decided Tugboat could change call signs and take on a new mission.
A few weeks later SOS was implemented and both Zack and I were both travelling to various onsite meetings.
Then this happened:
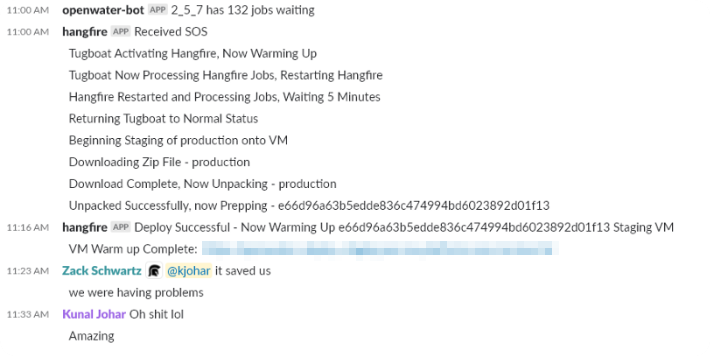
Hangfire died and came back to life. No intervention needed.
Mission accomplished!