-
Liberty Two-Four is now Air Force One

In the movie Air Force One, you might remember the scene where Harrison forward is bobbing around in the sky. His plane lost control and crashed into the ocean as another air force plane, Liberty 24 pulls him in.
As he boards the plane, we hear the pilot radio in to eagerly awaiting Washington, “Standby….Liberty 2–4 is changing call signs, Liberty 2–4 is now Air Force One”
Of course we all know the majestic blue and white plane only takes on the name Air Force One when the president is on board, otherwise it is known as SAM 26000 (Special Air Mission).
SAM 26000 doing a flyby of New York City. The citizens of New York and New Jersey had not been informed in advance, and some thought it could be the makings of a terrorist attack similar to the September 11th attacks. Some people ran out of buildings and panicked in the streets. Some buildings ordered evacuations.[
I’ve mentioned earlier how important a name can be framing how one things about a problem. Today’s story talks about how we took this concept of a name changing to help us solve a serious engineering problem.
When you use a website and click a link, you expect that website to do something right away. However what if that link is something like Facebook’s “Download all of my Data.” User expectation for something like that is some process will run in the background, and after some time you’ll be emailed the results.
The technique of running a process in the background is certainly something you could take for granted, but it’s the kind of thing that keeps websites alive when done right.
When we first rolled out background tasks and reports in 2012, we used a very naive method. We would run reports in the same thread pool as the main web request, which meant as we hit high web traffic we’d end up with reports simply not running.
In fact by early 2014 we started getting support tickets claiming reports simply weren’t running. Turns out those customers were right, about 30% of the time when you’d ask OpenWater (then called awardsCMS) to run a report you’d come back with nothing. Sometimes you’d only find out after hours of waiting that there would be nothing coming.
Around that time we scrambled for something that would help and Zack came across a tool called Hangfire. Hangfire intelligently ran jobs in the background and would retry them in case something went wrong. After a few months we had Hangfire implemented and without much fanfare complaints about jobs failing dwindled down to about 0.
2014 was also noteworthy because it was the year we re-branded from awardsCMS to OpenWater. This name that I was originally against, ended up being the backbone of how we build systems at the company.
The first tool we built in the OpenWater era was SONAR. SONAR is undersea technology that sends audio pings to receive data about objects. We were using a variety of software systems to keep our business going. Besides the platform itself, we needed customer support software (Zendesk, then, Intercom now), sales tracking software (Salesforce), and billing software (Xero). SONAR was the tool we developed that constantly pinged all of these systems and allowed for data sharing between then. For example if a sales person wanted to know which support rep was working on the customer they signed, SONAR would come through and link that information for them.

Naval SONAR in Action 
Screenshot of Sonar v1
If you have been to Seaworld or seen Blackfish you know all about killer whales. In sales terminology, whales are the “big accounts” so for us, we needed a cost effective way to find out who these people might be and how we could reach out to them. Our sales research tool was aptly named Orca.

In 1990 spy thriller, The Hunt for Red October, a Russian commander piloting a top secret high tech submarine defects and transfers this technology to the U.S. When we needed a tool for our competitor research tool, Red October quickly became our code name for this project.
There are only two hard things in Computer Science: cache invalidation and naming things.
— PHIL KARLTON
I’ll leave the article for cache invalidation for another day, but Phil Karlton, a master of design and computer architecture was spot on when he said that naming was an insane challenge. Besides computer science, the social scientists at Freakonomics taught us how a person’s name can change their whole outlook and lot in life.
After we came up with all of these fun names for our internal tools we set out a rule — we can’t start on a new project until we come up with an appropriate naval related name for it. We realized that if we had the right name for something, we would build it following the appropriate metaphor. 90% of computer science is thinking, so if we spend a lot of time thinking about a name it also means we spend a lot of time thinking about why something has a name.
Our software operates in the public cloud, we mostly rely on Microsoft Azure for our computational workloads. I mentioned earlier how the backend of our platform runs on Hangfire, the front-end is powered by web servers running on Microsoft Azure App Service. When our servers are under extremely high load, some of our web servers would crap out. Since we always run multiple copies of our software, if one server was acting funny we would get reports along the lines of “the page seems to take forever to load, then its fast, then its slow again, very bizarre.”
Under high load, if a server starts acting up, Azure App Service is supposed to take the server out of rotation, restart it and bring it back online. This was the earlier days of the cloud though, so in some cases a node would get stuck — it would be dead, but not yet be taken out of rotation. This created the phenomenon described above. The only solution at the time was to stop the entire service and start it, doing so would guarantee us a fresh batch of new servers. The problem is under high load if we stopped the service it would mean a full 10–15 minute outage when several thousand people are using the site, it was better for us to hang on with intermittent complaints than an avalanche of anger hitting our support lines.

USS George Washington to begin hull swap with USS Ronald Reagan In the military a Hull Swap is an exercise where the crew of one ship finds its way onto another ship. Often the vessel they are on is need of major servicing and needs a new crew to do that work. To stay ready for operations they need to get onto a new craft.
Hull Swap was the perfect name for our tool to help us fix the stuck node situation. We realized if we could transfer all traffic from the impacted environment, restarted that environment, and then sent traffic back once all was fixed we could get around the stuck node issue without any downtime.
We are now in 2019 and Azure App Service has come a long way. The idea of stuck node isn’t something we really have to worry about anymore. The technology we built for Hull Swap however lives on with a new purpose.
From 2012 to early 2018 just about every morning my routine was as follows:
- Wake up and check for new updates that are ready to be rolled out (e.g. bug fixes)
- Review the code and then copy it to App Service 1
- I’d then shave, roughly a 6 minute process, and then begin copying of the code to App Service 2
- I’d hop in the shower, roughly 10 minutes, just in time for the copying to be finished
- I’d then finish updating our platforms and doing some quick checks
Major releases were even more hectic, I would wake up around 2 to 4 AM and begin a checklist that could take anywhere from 2 to 10 hours. Often I would have to give up a Friday or Saturday night (or both) each time we rolled out an update. Not the best way to spend my late 20s, but I was determined not to let this process enter my 30s.
Using the technology of Hull Swap + a few modifications we implemented our latest tool. After my morning code review I now click a single button and Tugboat begins its journey taking our code from the staging environment to our live environment. Tugboat then performs a Hull Swap with our live environment. With no downtime we get updates sent to the platform every morning. Major updates can now be done during slow periods (e.g. Sunday morning), instead of the middle of the night.

A tugboat working hard on the open ocean (Wikimedia Commons)
With Tugboat in full operation and Azure App Service working really well, I could start to add back normalcy to my morning routine. One of the first changes I made was to make sure I hit the gym in the mornings. As I could clock in each month of stability and perfect up-time I started feeling comfortable working out without my phone.
Big mistake.
On a Thursday morning during February, I return to my locker. 2 missed calls from Zack. I load up slack, I see our support chat room blowing up. This can’t be good.
I get Zack on the phone:
- Zack: Hey man…none of our background jobs are processing
- Kunal: What do you see in Hangfire?
- Zack: Hold on let me look….
- Zack: Oh s*(@!. 4,000 jobs and its increasing as we speak
It looks like that stuck node problem had a cousin and that cousin didn’t like Hangfire very much. The way we fixed this was a similar process to the stuck node problem, restart the servers and wait it out.
This problem happened a few more times during our busy season and then hid away. The best we could do was detect when it was about to happen and then implement the manual process. February ended and we went back to our smoother months. March, April, May, June, all went by fine. By the time the summer hit, we forgot we even had this problem.
Then seemingly out of nowhere the detector lit up in early September. Fortunately we were at hand to quickly solve it. Then again it happened, this time at around 3 AM on a Wednesday. We were not so lucky, it wasn’t until around 7 AM until one of us noticed and fixed the problem. Our European customers were not too happy.
We had to do something about this. We learned that the people who maintain Hangfire rolled out an update for this situation. It would take us about 3 months to implement the fixes in OpenWater, so what would we do in the meantime?
We got to thinking — of course we started with the name. We started talking through our current solution. I can’t remember which one of us said what, but here are some of our notes
- “Hangfire really needs help when its under heavy load”
- “Yea, its like when it is about to die it needs to make a call for help”
- “Dude, Save Our Sever, F*&!@ SOS”
- “OMG, SOS! Totally perfect name”
- “But who would save it, we’ll be asleep”
- “Dude… Tugboat”
- “Dude…”
We realized our emergency procedures altered Tugboat to act like Hangfire. That would buy us a precious 5 minutes of processing time while the main Hangfire servers were restarting.
Like Liberty 24, we decided Tugboat could change call signs and take on a new mission.
A few weeks later SOS was implemented and both Zack and I were both travelling to various onsite meetings.
Then this happened:
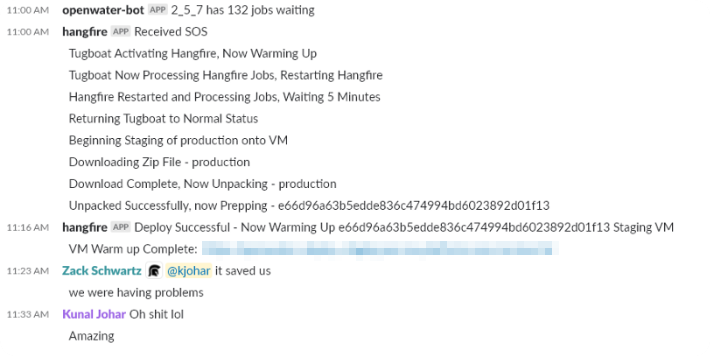
Hangfire died and came back to life. No intervention needed.
Mission accomplished!
-
We Have Trinity!

About 2 weeks before Kanye West rose to internationally acclaimed fame, he came to George Washington University’s “Spring Fling” (undergraduate spring concert) and performed several soon to be hits alongside John Legend.
Among his songs was “Kanye’s New Workout Plan.” After a few loops of “eat your salad no dessert, get that man you deserve” he stopped the music, grabbed the microphone and proclaimed, “who better to remix this song I made, than me!” He was right, spun up a fist pump evoking remix that made the students on the university quad go crazy (precursor to going nuts / ape-s****).
Kanye is an asshole for sure, but he is also a master at his craft. In his song Spaceship he goes on to say, “Lock yourself in a room doing 5 beats a day for 3 summers.” He knew hard work and consistent work is what leads to mastery.
I’m not a musician, but I have to imagine there must be that moment, that ah-ha, I got it, this is it that the Kanyes of the world must feel when they get the beat just right.
But is it an ah-hah? Or is it something deeper within us?
A much younger Zack and Kunal. About 7 years before the events described below. Zack just finished his prototype that makes the screen turn the color your shirt.
I started thinking about one of my favorite musicians and the journey he must have taken to realize this 3 second clip is the ah-hah for his puzzle. Let’s hear it together.
Do you recognize it? How about this clip:
It is the theme song to the original 90210 clip from the 1990s era TV show.
So what exactly were Thomas Bangalter and DJ Falcon thinking and how long were they working on their song Together?
The song itself starts with a question, “Are we in this thing alone or are we in it together?” Together debuted in August of 2000, a repetitive loop with the single word Together. How many times did this loop play, and how many different samples did they have to play until this 3 second clip hit them like, YES.
…here is the full track.
Sure, I get it, Together may not be your jam.
Thomas Bangalter produced music as part of a few other groups. “Ooh baby, I feel like the Music Sounds Better with You…” — that international 1998 hit, Thomas Bangalter (Stardust).
Music’s got you feeling so free, you have to celebrate? Celebrate and dance so free? One More Time, an instant classic from 2000 by Daft Punk (Thomas Bangalter and Guy-Manuel de Homem-Christo).
Who can create a better remix than the masters of the original art themselves? In 2007, Daft Punk toured the world, and put on this finale.
Human After All, Together, One More Time, Music Sounds Better Than You — riffs from each of these songs pulled together into 10 minutes of nostalgia and excitement for their fans.
About halfway through, 5 minutes of crescendo build up and the duo drops the 90210 beat as the opening to the second crescendo bringing back their mega-hits like One More Time and Music Sounds Better Than You.
The crowd goes totally nuts, one more time, as they close out their concert.
When Zack and I decided to go forward with Api2PDF, Tim opted out. This meant we could not use OpenWater resources to build out our idea.
In the old days, I would design the UX, then I would write a coding plan, I would code myself, then figure out how to launch the product. Tim figured out how to sell the product and after he sold it, he was also the first support rep we had.
Over the years we have been fortunate and seen our teams grow. We now have a full team dedicated to support, another team dedicated to sales, and yet another who who is in charge of building the product. It is to the point where I can discuss my vision with our software architect and UX designer and a few months later the features appear in our software.
We wondered, without company resources at our disposal, would we have what it takes to stay motivated? Would we be able to stay focused enough to build a minimum viable product and would we be energized enough to actually get it passed launch?
We went back to our roots. How can we build something from nothing? We thought through the components and our expertise:
- (ZACK) Billing System
- (ZACK) Customer Portal
- (ZACK) API Usage Meter
- (KUNAL) Website to Advertise Ourselves
- (KUNAL) The Actual Convert to PDF API
- (ZACK) Implement Kunal’s Crazy Idea
We got started and set aside a small budget to help us offload work to affordable overseas developers. After a few weeks of moonlighting, we were ready.
Our goal with Api2PDF was to make PDF generation so cheap that we would take the bottom out of the market. To make that idea work, we needed to get the best of the both worlds of serverless technology. Serverless, at least in theory, means you pay only for the compute power you use, by the second.
Amazon Web Services (AWS) provides a serverless technology called lambda. Microsoft Azure provides one called functions. The crazy idea was to split the workload across both providers to get the high power of AWS with the accessibility of Azure.
We were ready for our test day, Trinity.
Zack arrived a few minutes before me on a Saturday morning. He had all 3 of his monitors fired up with the various components that we needed to glue together.
On one monitor, Visual Studio, fired up in debugging mode, running the web portal; on another monitor Azure Functions console, where we could see PDF processing in real time; and in the third a Node.JS test app ready to battle test the whole apparatus.
He clicks GO .
Data starts flying across the screen:
- PDF Generated (0.000021 billed)
- PDF Generated (0.000011 billed)
- $1 Monthly Charge Billed
- Auto Renewal Hit
- Large PDF Generated (0.030011 billed)
- Large PDF Generated (0.500011 billed)
Thousands of messages like the one fired off, we stopped the experiment and shared high fives and a few expletives.
Trinity was a success!
I wondered out loud if how we felt watching numbers fly across the screen gave us the same feeling that Dr. Feynman felt during trinity. (Trinity was the first test detonation of the atomic bomb. While the bomb overall has been controversial, when trinity happened all of the people working on the project basically were like “holy shit, this thing actually works.”)
I believe this feeling of wanting to know, can it be done, more than anything else is the secret sauce behind invention and art. The ah-hah is just the first step, the first taste to wanting to create more.
*As a side note Kanye West / Daft Punk collaborated on Stronger. It was actually a collaboration, not just Kanye sampling. Daft Punk re-composed their loops of Harder*Better*Faster*Stronger.
-
Founder Stories — About Project ETOPS
The hidden gem in naming our company OpenWater was the instant name generator when it came to new projects.
When we built a system to help our sales team find whales, we quickly came up with the name Orca. The naming continued as we built SONAR, Tugboat, Islands, Hull Swap, and the Ship Yards. I plan to share the story behind each of these tools, along with the OpenWater name; but today is about ETOPS.
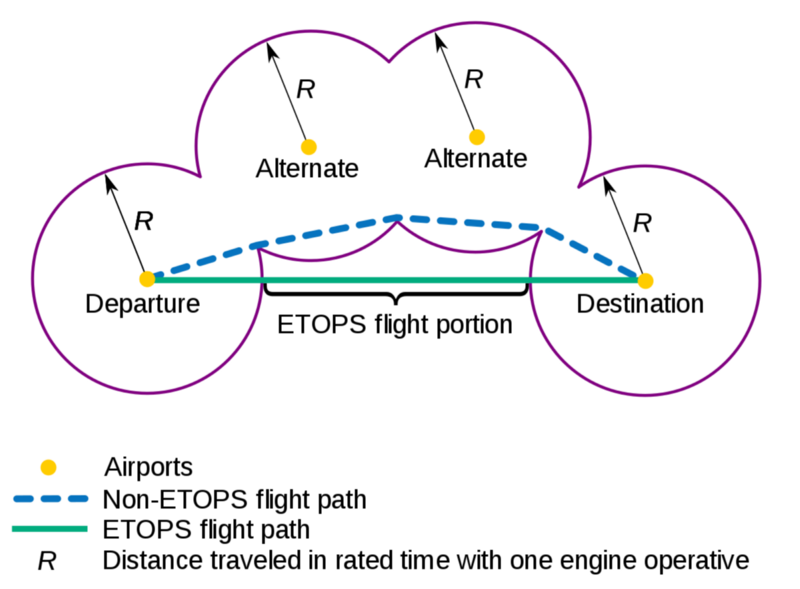
What the heck is ETOPS? ETOPS stands for Extended-range Twin-engine Operational Performance Standards. ETOPS is a certification used in the aviation world to help ensure planes don’t crash when they travel across the ocean, just because one engine went out.
Prior to ETOPS, the only planes that were allowed overseas were the gas guzzling 4 engine behemoths. The idea behind ETOPS was that if a plane has two very reliable engines, and each engine was maintained by distinct teams, the likelihood of a two engine failure was so low that the government agencies would deem such flights airworthy.
Each year, in January, the OpenWater platform takes a beating. Hundreds of awards programs around the world have their submission deadlines resulting in millions of entries flowing through our system in a short period of time. This January surge caught us by surprise the first year and managed to knock our systems totally offline for a few hours.
Our solution then was to get the biggest and best server we could afford. Our thought process was that if we could run one server at 10% capacity, we could kick the can down the road until we had a better idea.
By the time January 2014 rolled around, this one server was hitting 30% during peak usage. As each year passed, I breathed a sigh of relief that my solution was holding strong. January 2018, this server peaked at 60% and I began to worry.
Even if we made it through January 2019, I knew by the time 2020 rolled around, it might be too late. When tech companies kick the can down the road sometimes it turns out to be more like a massive kick in the ass.
A relational database is one of the hardest components of a platform to upgrade. It’s old technology that is from a time when people were used to downtime. Sure if we could just turn off the server for 2 days no problem; but in today’s world our customers rely on a platform that just works.
Microsoft developed a modernized version of their database engine called SQL Azure Elastic Pools. As the name implies, these elastic pools can stretch to meet capacity as our needs grow.
Moving to SQL Azure was a must do move for us to solidify our business for another 10 years of expansion. This was also a must do move before January 2019, in fact it was a must do move during the summer of 2018 while our usage is at its lowest point.
The entire summer was spent planning for and testing our approach. We ended up executing the procedure over labor day weekend.
I called this project ETOPS because it reminded me of the extreme care that we needed to take at each step. I also knew if we failed, we would have a catastrophe. Some customers would lose data, others would face significant downtime. Besides our customers being frustrated, our support staff would feel disgruntled at exactly the time they need to be on their A game.
I would like to say, if we got this wrong we wouldn’t survive as a business. As such, I’ll defer to the other way ETOPS is described by pilots, which is:
Engines Turn or Passengers Swim. -
Founder Stories: Why We Built Api2Pdf

Excitement over API2PDF Launch The year was 2006. I was 21 years old and fresh out of college with a newly minted degree in computer science. While I had acquired a stable job with the government, at night time I would scour the Gigs section on Craigslist to fuel my side hustle. I would reach out to anyone looking for help building software or databases. The plan was to acquire enough customers of my own to begin a full-time software consultancy.
The first major project I landed was PriorArt.com — a patent search and discovery firm. PriorArt was drowning in reams of paper that was the result of thousands of faxes, printed emails, and legal documents. I had to provide a mechanism to store all of this information into a centralized, web accessible, online system. I was naive and had no idea what I was getting myself into with this project or the challenges I would face.
The greatest obstacle to building this “paperless office” centered around PDFs. Every physical piece of paper PriorArt dealt with needed to be converted to a PDF in this online system. The PDFs were heavily used for “Docket Agreements” — mini-contracts or statements of work.
To make things more complicated, one requirement I had to meet was that the system needed to run in a shared hosting environment. The mid-2000s was a transformational time for web development. It was still very much the wild west. Amazon Web Services hit the market, but it would be several years before I would pay much attention to it. All I knew about shared hosting back then was that you would pay $10 per month and you would be allocated some space on that server to run some code. Security and server isolation were distant thoughts.
My first attempt was to use a component called ABCPDF, miraculously still for sale. As with most .NET components back in 2006, ABCPDF required some wrangling to get the DLLs running in a shared hosting environment. EasyHosting, the hosting provider at the time, rubber-stamped my custom DLLs and we were off to the races. PriorArt was generating PDFs.
Barely two months go by and providers started to wise up to the security holes posed by allowing custom DLLs in shared environments. Microsoft issued guidance on a concept called Medium Trust which ensured that neighboring customers on the same server could not interfere with each other. ABCPDF required Full Trust, so that was the end of that.
My backup plan was to run PDF generation on a shared host using PHP. I turned this into an API only accessible to the .NET platform. After a lot of trial and error, I came across https://tcpdf.org/, a library that persists to this very day. At the time, TCPDF, provided HTML to PDF conversion, but did not allow the use of external stylesheets. It was immensely painstaking, but I was able to convert all of my templates into a format suitable for TCPDF.
PriorArt was live and I was hopeful I would never have to go through PDF hell again.
That wish did not come true, but I did succeed in leaving the government and started my software consultant business, vOfficeware and then later nonprofitCMS. In 2009 I was approached by Cambridge Information Group (CIG), a private equity firm that owns several education companies including B2RMusic.com and Sothebysinstitute.com.
My PDF journey continues. I had to generate PDFs of statements and invoices for students and their parents for the online portal of this music school. CIG had their own servers though, on premises. I was back to using ABCPDF with Full Trust and I forgot I had ever faced any PDF problems at all.
Fast forward to 2012. By now my company had launched its own product — an application and review platform that helps organizations run their awards, grants, and scholarships. We rebranded as OpenWater and left consulting work behind.
Part of any applications process requires a form where an applicant submits their information, and will often have the ability to upload files, such as transcripts or letters of reference to produce a full application package.
Once again I was thrust into PDF purgatory. When OpenWater first launched, we were running on Mosso, a cloud-based platform that allowed for Full Trust packages. We decided to go with the open source iTextSharp library to handle our PDF needs. Almost immediately after we launched, we found out iTextSharp was pivoting their licensing model and would no longer be free for commercial use. We stayed on their old version as long as we could until a suitable replacement came out.
WKHTMLTOPDF fell into our laps like a gift from the heavens. It was the rendering engine of Google Chrome and Safari (WebKit) that created reliable PDFs time and time again. By this point too, the idea of renting a virtual machine from a cloud provider became affordable. We were able to swap out iTextSharp with an API call to a secret VM that would sit idle and generate PDFs as we needed it to.
As we expanded OpenWater, we continued to find new ways of linking up to this secret API. Having a VM dedicated to producing PDFs saved us many hours when we had to add PDF functionality on any new project. However, we were headed down a path we would later come to regret.
As the success of OpenWater continued, our PDF needs would increase as well. We went from generating dozens of PDFs per day, to hundreds, to thousands. In 2016, we rolled out a feature to let our users download their data to PDF in bulk. These were not your average PDFs. In many cases, the PDFs could be thousands of pages long. We saw our PDF usage explode. Tens of thousands of PDFs were pulled daily! Our single VM dedicated to producing PDFs was getting crushed, would shut down and require restarts. With so many projects depending on this single point of failure, everything was coming to a grinding halt. Customers were upset and could not understand why our system struggled to generate what was a simple PDF.
We were able to temporarily mitigate the issues with some combination of scaling the server up and out. We found we were stable again at around a burn rate of $400 per month to keep this now cluster of VMs running.
This reprieve was short-lived. We rolled out the ability to include images and merge multiple documents into a single PDF. With the increase in both PDF size and raw processing power, our PDF servers could not keep up with the load. We could not even get them to respond to a reboot request.
We scaled up to the max, and now our PDF generation costs surged to nearly $4,000 per month, but the inundation kept coming.
A few customers ended up being a chokehold for our entire platform’s PDF needs. We had no choice but to cut off these customers from the PDF engine. To help these customers out, we had to work through the night to generate their PDFs using our local computing resources so they could make their deadlines.
Our customers have come to expect reliable PDF generation and do not understand what goes on behind the scenes to produce massive PDF files at scale. Admittedly, when we told our friends about Api2Pdf.com, their first reactions were “I can just print to PDF, how hard can it be?” We knew that $4,000 per month was not sustainable for a steady state server that will be used sporadically for PDF generation.
Over coffee, my colleague and Api2Pdf co-founder, Zack Schwartz, proposed the idea of using Amazon Web Service’s Lambda service for our PDF generation needs. On paper it seemed like the perfect solution. AWS Lambda would give us computational power for each PDF request, independent from the next request. If we have 1,000 people needing PDFs all at once, AWS Lambda would give us the resources we need on the spot.
Over the 2017 winter holidays, we set out to rebuild our PDF virtual machine cluster into a set of AWS Lambda functions and roll them out before our January busy season kicks in. If we could build a drop-in-replacement for WKHTMLTOPDF, we could always just revert back to the $4,000 per month solution.
Throughout January 2018 — May 2018, we continued battle testing our lambda functions. The result worked out way better than we could have ever expected. Our PDF generation stayed up throughout the entire busy season and our costs dropped from $4,000 per month to a range between $31 and $61. We generated several hundred gigabytes worth of PDFs.
By March, we realized we were on to something. If we put a bit more effort, we could offer a tool to all developers at a nominal cost. PDF Generation really sucks — there are a lot of great resources out there and a lot of free ones for those developers who have the DIY mindset. We wanted to create a tool for those who just don’t have the time or are overworked and have too many priorities. In the end, customers just want things to work.
Api2Pdf.com launches today and is a wrapper around popular tools most developers already use today:
- WKHTMLTOPDF
- Headless Chrome
- Libre Office
- Merge / Concatenate PDFs
Our goal is to simply make it easier to use the wheels that already exist at the lowest cost possible. For about $1.50/month, we think that 90% of developers can have their PDF needs fully met. We also believe our service can scale for the remaining 10% that have heavy duty PDF generation needs.
Cheers!
-
No more Vendetta
Back in 2007, when I was still operating as ComputerHelpDC I created a quick database called ScheduleC to help keep track of Schedule C expenses that could be written off taxes. With the start of vOfficeware we saw the need to bill clients in a recurring manner, so I decided to build a generic invoicing platform that others could use + allow us to eat our own dog food and use it to bill clients.
As we continued to grow, we had to start to track revenue in different codes. Instead of refactoring vOInvoice (which was used by perhaps 40-50 clients — but very few who would pay), I built another system we called “secure vo” — simply because it was hosted at secure.vofficeware.com. The key difference in functionality was that while vO Invoice could do automatic billing, secure vo would store credit cards and charge them — not exactly PCI Compliant.
Unfortunately that server has been killed off, so I don’t have a screenshot to take.
Once we started selling Awards, we quickly realized it we needed a tool to help track that business. Zack’s first project was to explore .NET 4.0 and he built Vendetta our first license restriction system.
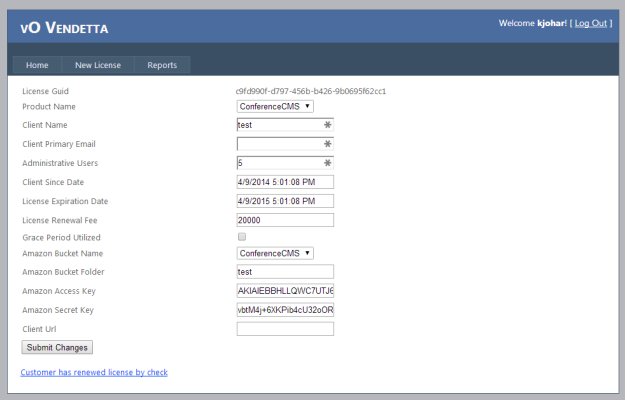
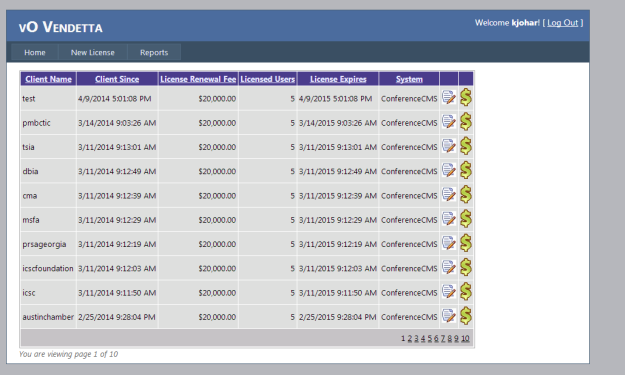
What a joke that was — we stopped enforcing licensing restrictions almost out of the gate and this system became a glorified license key generator. Zack continued to work on Vendetta, by this time he wanted to learn AngularJS and our sales were growing to the point where we needed a system that could help track commissions on complex deals (split payments, multi-year deals, multiple people getting commission).
We worked together to roll out this system. It was clunky, but it supported everything Secure VO did + commission tracking on recurring and non-recurring deals. It also contained a system for support people to log into clients with. (Prior to this we had a google doc that had hashed links). Pretty crazy to think how ghetto things were. This was a part time project for nearly 1.5 years. It was slow, and buggy.
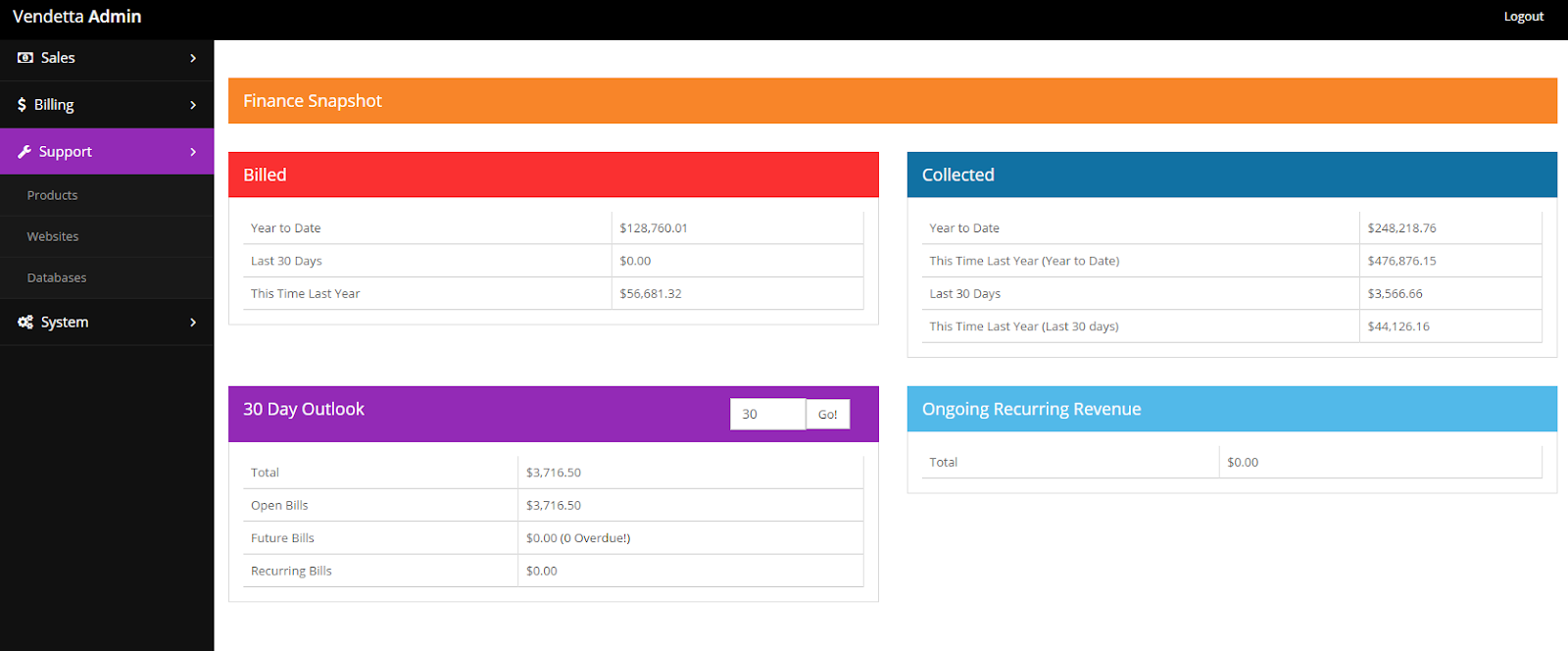
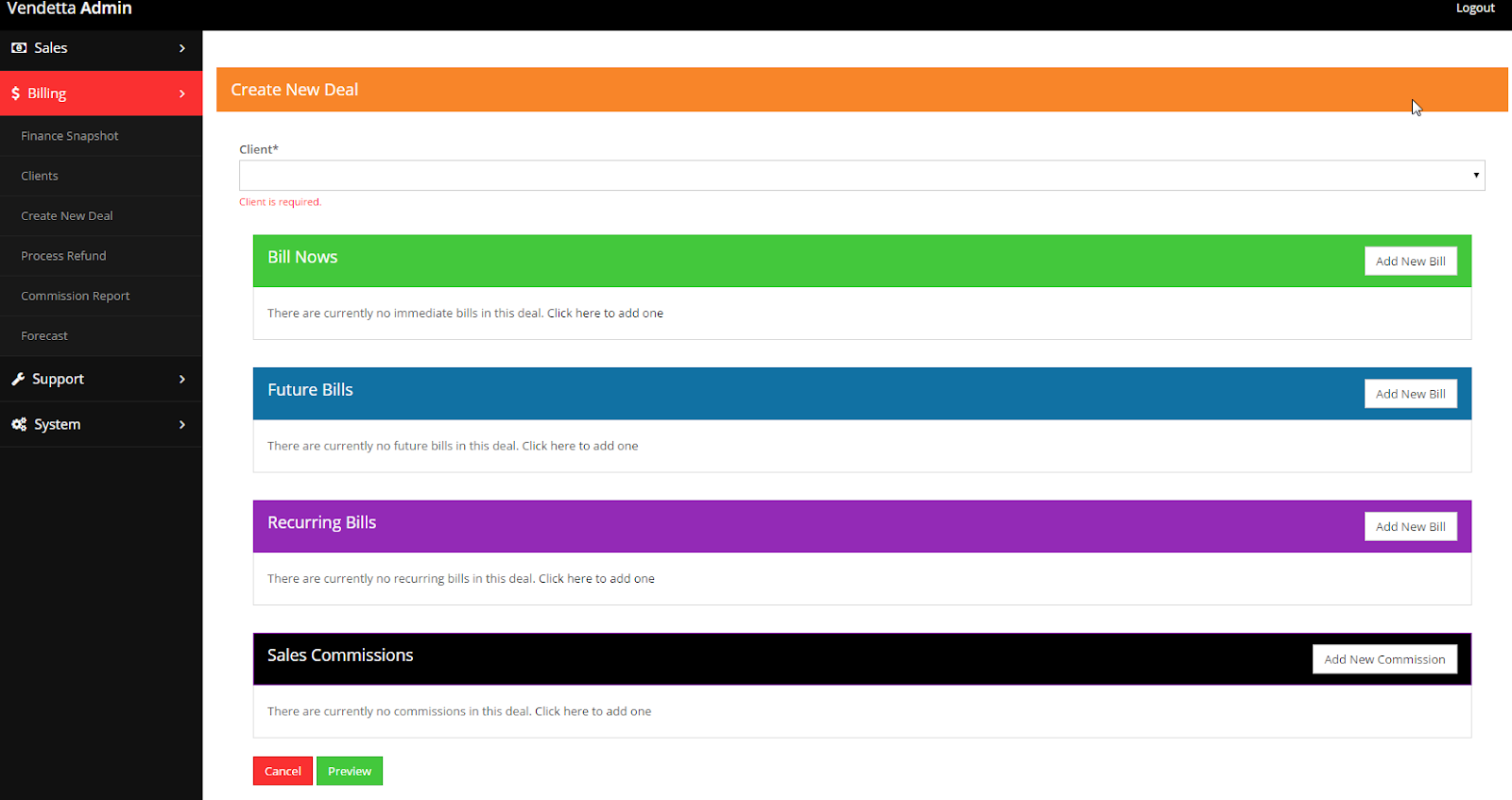
It had one key flaw, it didn’t produce invoices, instead it relied on statements. Like many of my bad decisions, I based my solution based on accounting that an accountant would appreciate, not a common person. Thus each month resulted in confusion and frustration for people who had to pay our bills. Eventually we built in a hacked invoicing workaround but by this point Vendetta’s days were numbered.
As we built up Vendetta we also used it to synchronous information from multiple systems. Today marks the last of those syncs being turned off (with Basecamp).
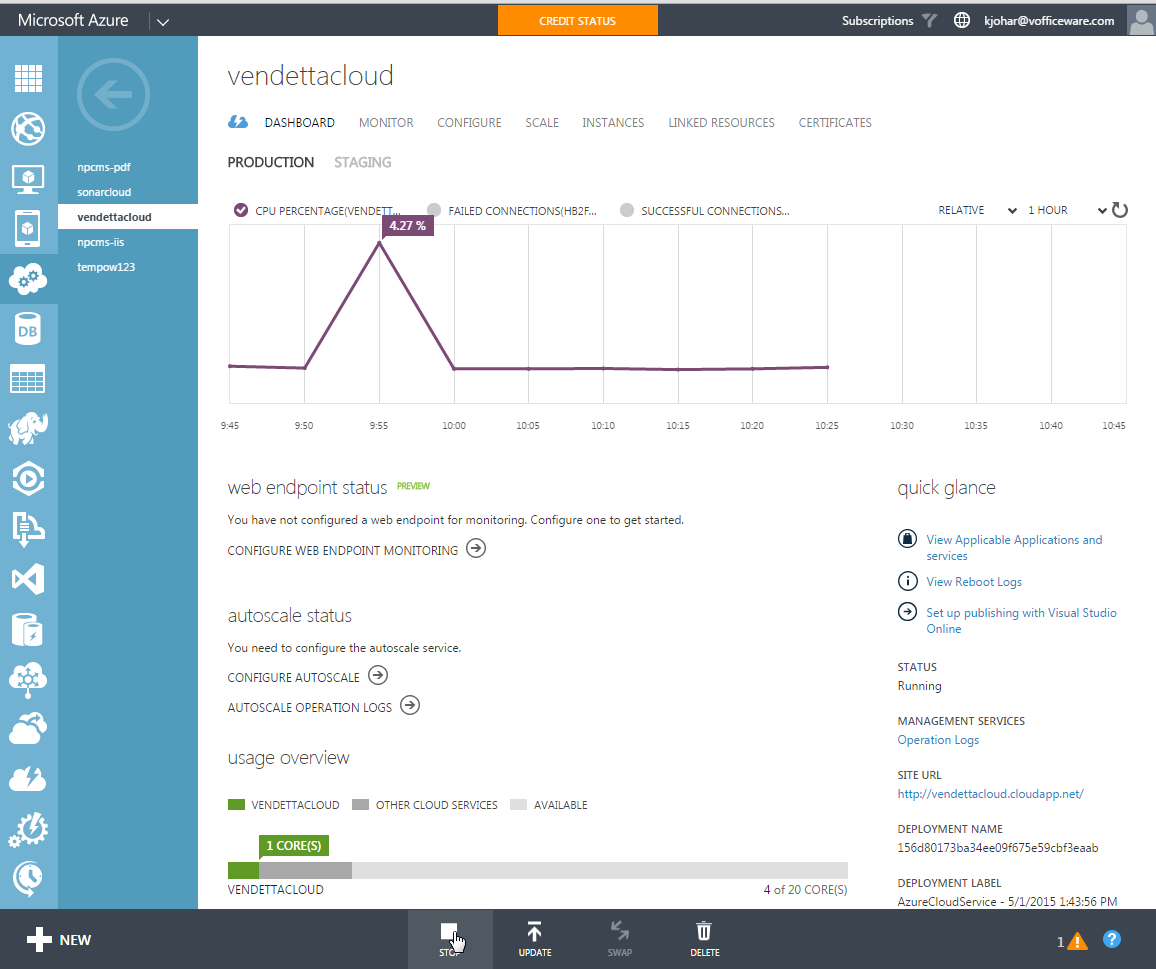
We learned a ton building Vendetta. Namely AngularJS, using Azure Cloud Services, and the limitations of Azure Cloud Sites.
A few months ago we decided on the replacement for Vendetta. Our whole strategy shifted from building these super custom tools to match our specific workflow, to finding the best of breed software to solve our business needs — then sacrificing the fringe cases that weren’t super important.
Part of making this decision was deciding that the NonprofitCMS business was no longer relevant. The consulting business model was way different from a SaaS sales model, so that decision too allowed us to simplify things.
Keeping the Open Water theme in mind, we named this project SONAR. We were able to stand this up in a few weeks of development by following two principles:
- Find systems that solve core needs
- Use APIs to make integration happen
- Refactor but mostly copy previous integration code from Vendetta
Now we solve our most common needs as follows:
- Commission Tracking
- Sales tracked in salesforce
- Billing automatically tracked in Xero
- Sonar combines both feeds of data to compute monthly commissions
- Provisioning and Billing Clients
- Client Licensing Restrictions tracked in SONAR
- Billing tracked in Xero
- SONAR then combines data to make sure clients have paid up
- The OpenWater Platform queries SONAR to lock out users who haven’t paid
- Ensuring Only Supported Admins Get Support
- Supported Admins Tracked in Xero
- All Help Tickets get pushed to SONAR before they are processed and are tagged with SUPPORTED vs NOT SUPPORTED attribute
We frowned upon this strategy earlier because we thought we could do it better and cheaper if we went custom. In hindsight, we spent hundreds of hours building Vendetta and supporting it. When needs changed we became a bottleneck to our own progress. Perhaps when we set out on this course years ago, the APIs of these platforms were not robust or easy enough to work with, but more likely it was just overconfidence in our own skills and ability to code quickly and bug free that held us back.
Here is a look at SONAR.
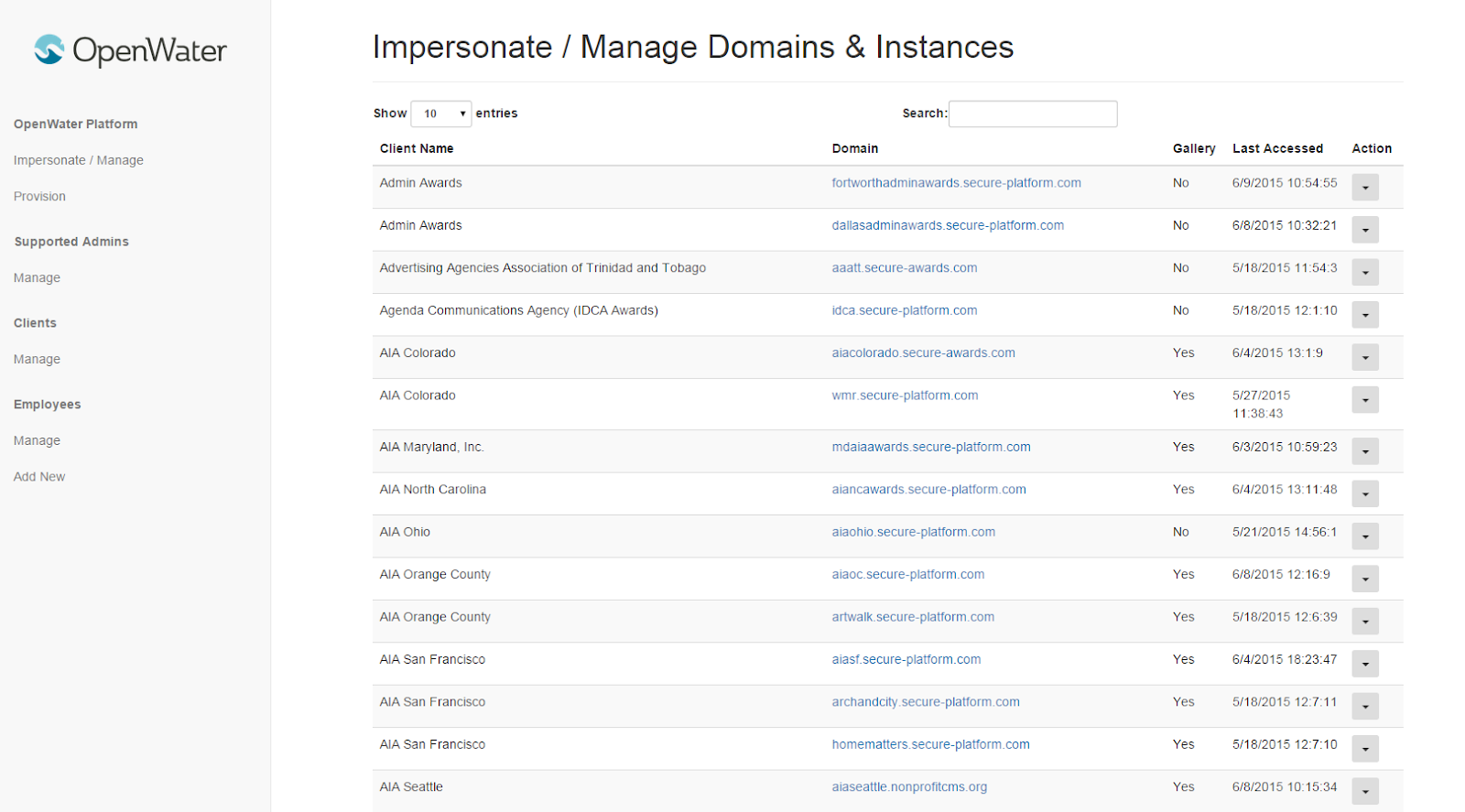
-
Living on the Edge
The last few months have been just unbelievable. We fired David, had to let go of Jason. One day I might blog about those, but I want to quickly jot the more serious part of the business:
This week we hit near bankruptcy — $1,000 left in our bank account. Granted we wouldn’t have gone under, but it would have meant 5-6 people losing their jobs next week + the majority of personal savings going into the company to build a way out.
The bottom line is we grew too fast. We hired 9 more people between December and January and bet heavily on a sales strategy that should have “worked on paper”. At the end of the day, I should have known better and made a bigger stink about numbers not tying out.
E.g. our plan was to increase our sale price to justify the extra commissions we’d be paying. The problem was that we paid our salespeople a flat commission (e.g. 15%) regardless of the discount amount applied to the deal. Thus a 30% discount would still pay out 15% of the newly discounted price. The problem was that even discounting 30% pushed us at or below the edge of profitability. Multiply this out and we have one problem.
A second problem came with people crowding out each other’s work. For example our newly hired 4 lead gens:
– 1 is a success
– 1 was fired
– The other two are pillaging each other’s leads and also taking leads that should have come in from our website by messaging them on live chat just before they fill out the forms.
In my view we were paying 4 salaries to get the results that probably 1-1.5 people would be producing.
Finally we hired fully fledged sales people and underestimated the training time needed.
Tim agrees, the future plan would be incremental growth. We pushed really hard to be on track for a $2.5MM number this year that we pressed ourselves hard.
At the end of the day we trusted too many people to work their asses off with a no excuses attitude. It was naive and we fortunately got a fresh loan to tide us over for a few months, albeit at a 15.9% interest rate.
Coming so close to the edge though even had me look at other job opportunities to see if I could work 40h/week + run the company to offset my salary. Going through this process, I realized how I really would not want to contribute somewhere other than to myself.
So I’m back and stronger than ever before. I plan to finish the Abstracts part of our software package . Website, marketing materials, sales materials, demos and development. I plan to be a one man show for the next 9 months to build a second product wing. I’m challenging myself to produce $150,000 in revenue and get about 20-25 customers in the process.
The best thing that can happen is the kinks in our Award Sales get fixed and they end up knocking it out of the park. But I don’t want to be pushed to the limit with no backup plan again.
Maybe we choose to abandon abstracts again, but doing so I’ll go in knowing 100% that we have a strong plan to succeed.
We’ll get there eventually.
-
Making Profit vs Growing the Company
I wrote this email to Tim and Zack. I realized the amount of time Zack especially, and me to a lesser extent have been working on the weekends has generated around $50k. Since the company isn’t profitable I am treating this money as a direct subsidy to one of our non-essential staff members. I’m a bit frustrated, but writing this out helped me understand what I need to do about it.
The bottom line is that we keep growing revenue, but adding on expenses that are less than optimal. I proved earlier this week that if I spend an hour brainstorming, I can come up with 8 blog posts. I found a writer who can do a good job with my brainstorm input.
Translation, 1 hour per week x $11,000 per year will get me more output than my own marketing employee. We spend about 5x that much on her after all expenses are incurred, and I bet we spend more than an hour a week managing her.
Thinking like this is needed to make sure we don’t waste time and money. Having said that we do have a goal of having a fun, bustling company. The solution is not to get rid of any stuff, but to think about how can we make sure we are getting real solid output out of them that we couldn’t have gotten otherwise.
Hey guys,
Let’s pencil in a weekend discussion to go over this in the next week. I scheduled for Sunday 7/27, but feel free to reschedule.
One of our frustrations with our overseas staff and local staff is that we can’t just say go and get something done. We need to handhold.
I think we need to come to the conclusion that we can’t do that with our current staff either. Each time we do, we end up wasting a lot of time and money compared to when we plan things out.
Recent examples:
Marc. Hear nothing, see nothing, work gets done, but a big timebomb was waiting to go off. The solution only came once Zack took the lead on this.
Miriam on Scripted. Several low quality articles produced, lot’s of editing time, lot’s of time wasted bombarding Tim with questions, and her having writer’s block
Managing David. When we hired David, we gave Timmy 2% to deal with the mess. Tim Spell ended up dealing with most of the mess. Sure Timmy helped out with closing deals on his vacation, but Tim Spell really helped rectify this.
Mailgunner Data.com Blasts. We asked the sales people to come up with a plan. The plan was to waste our money. The early discussions we had about this included semi-targetting, but there was never a plan developed that was written. Timmy wrote a few paragraphs that was the closest thing we had to a plan.
I guess it is human nature. When you give someone a vast amount of resources ,there will be waste. We’ve grown this company so far by working our assess off and spending money very carefully.
Miriam Paintings – Another example of loose negotiations going bad. Miriam through out an initial # of “thousands of dollars for a 4′ x 3′ painting.’ I did my own homework this morning to understand where she got that # from, of course she threw out something on the high end.
This is a semi-organized email, but my high level point is, we work our assess off. The last thing we need is to be taken advantage of. It may not be people taking advantage on purpose, but it can be subtle things like Kyle working on the wrong priorities, or Miriam letting writers block be an excuse for low output.
My vote is to move away from a hands-off culture and move towards a hands-on one. By being hands-on we are constantly innovating, cutting costs, and getting to be more efficient.
I’m not saying we micro-manage, but a hands-off approach is too costly.
The best solution for sure it to only have team members that can lead themselves and push the envelope, but at some point we need to recognize how rare that is.
To put it another way. The work Zack and I did over the last 4 weekends will generate around $11,000 worth of money. For $11,000 + 1 hour a week of our time we have 200 blog posts and 5 guides. We are spending more than $11k + 1 hour a week on Miriam.
Right now we are spending money and working more to come up with that money. We are seeing results, but we can see much better results.
Going forward, my vote is to slow down a bit in terms of hiring. Setting a few major goals and making sure we get them.
Miriam – We spend $4,500 per month on Miriam. What do we want as output.
Kyle – We spend $4,500 per month on Kyle. What is the output we expect
New Salesperson and Salesperson Compensation – It takes 6 months to break even on a new salesperson. While Timmy may do a better job round 2, it will still be Tim Spell who picks up the pieces. I think before we ask the salespeople to come up with their own comp plan, we internally come up with one and hold our cards close so that we are not skewed by the first thing we see.
Kunal
-
What’s in a Name?
When we started the company, we thought for about 2 days to come up with our company name. We sell virtual offices! Duh vOfficeware; virtual office software. It made sense, we got a cool logo made, we had a tech looking vO brand made. We were really happy.
We never sold a single “virtual office.” We started releasing other products for invoicing, email, document management. vO Invoice, vO Mail, vO Paper. “What is VOPAPER?” “HUH? VOIN VOICE?” I’m confused. The name vOfficeware never really made it.
In late 2009 we launched “nonprofitCMS” — a content management system for nonprofits! Another great and logical name. It also was one of the main reasons we achieved such a high ranking on google — lot’s of people looking for a “nonprofit CMS.”
Well as of this year, we abandoned web site development. The shift has gone 100% to our product lines. We no longer plan to market exclusively to nonprofits; we need to target a wide net of prospects: magazines, researchers, trade associations, and corporations. We also offer a platform that helps automate awards competitions, abstracts for conference proposals, board of election votes, scholarship applications, and event registration. We struggled to capture “what we do” in a concise manner like vOfficeware or nonprofitCMS.
We could not come up with a good enough name for o.urselves; the best Tim came up with was “Open Water.” The problem with naming things is that the .com is never available. The owners of OpenWater.com wanted six figure offers before even considering a bid! We worked with the marketing company to help brainstorm names for us. They came up with a list of 150+ names that ranged from meh to really really bad.
The best they came up with was “Convergio” — since our software converges lots of data… or the scientific sounding 373 KELVIN (the boiling point of water). Neither of these .coms were available either; but they were costing in the single digit thousands. Then they sent us http://www.brandbucket.com/ — a site where you can buy brandable domain names at a list price (instead of an auction). We liked things like StackBot and Technoto.
The worst was “Olly olly oxen free” — I lost all respect for them for even presenting that to us.
As we thought it over; we needed to have good visuals to go on our marketing collateral. Sure convergio sounds cooler than OpenWater, but we’d face an uphill battle to determine what it means. Then we’d have to convey that brand and drill it into people. Also telling people on the phone kunal at convergio dot com would involve a lot of hell in spelling disasters.
Finally, we concluded that we wanted real words. This way the marketing company could hit the ground running. We decided to list a few names we could live with just to move on with the process. We settled on OpenWater and Kelvin — for domains OpenWaterTech.com and Kelvin373.com. At first I thought we’d put it to an office vote, but then I heard Tim start pitching open water to the team; once he’d leave the area, I’d go and make a pitch for Kelvin. Sneaky — but probably not the best way to make the company name.
In our elevator lobby, I just asked a stranger, “what do you think when you hear Open Water?” He answered “I think clear, transparency, trustworthy.” “OK — how about Kelvin?” “I don’t like Kelvin, it sounds weird”
FUCK
I liked Kelvin! I thought it could make a cool, futuristic sounding name. Kelvin 373 — the boiling point of water. The name really grew on me. @Kelvin373.com — easy to say — easy to type. What an ass, ruining my big pitch.
Zack and I came up with the idea of putting out a survey, ask our clients, ask our friends, and settle this. I asked questions cold turkey, like which name is better; but also drove people through our issues like hearing it on a phone or seeing it as a brand.
The closer the friend, the more hate that was spewed in both name options. Minutes after sending the survey email, I get a text from Connie: “Both of these names suck balls; one sounds like a plumber, the other sounds like an HVAC company.”
Alex: Where is the option for neither
Brandon: I like OpenWater and Kelvin; but not OpenWaterTech or Kelvin373 — I don’t see the option
Robyn: Kelvin sounds like the name of a fobby chinese man
Some friends asked, why not just use vOfficeware (something I thought long and hard about).
I described this process as choosing a presidential candidate. Neither option was good, but it was the cards we had to play. Every day we don’t have a name, we are a day late on our new strategy — and our backs are pressed up against a wall financially.
Outside of the friends though, the clients were more polite and overwhemingly chose OpenWater over Kelvin. Even OpenWaterTech was better than Kelvin373. I was shocked. I was beaten badly, 93% to 7% — with 70 responses.
We’re now going to be OpenWater. I have very little, if any, buy in from my friends on this. I figure their opinions are honest; and frankly I believe it myself. I’m sure over time, the name will grow on me and develop a meaning of its own. For now though, I’m happier to have this decision made and to move on.
-
1 Year from Success, 1 Month from Bankruptcy, and a Lifeline
In the beginning of December, I presented the plan for 2014 to the team. “Things are too easy, so we need to stir up the pot.” Well here we are a month later, and the pot has high entropy.
The wildcards we thought would give us cash simply didn’t pan out. AAF Member delayed their decision and are leaning towards no; and the $500k I wanted to borrow was rejected (big surprise).
Our gambles are in the infancy and are the source of my anxiety. I just won’t know for months if these work out; and if they don’t we’re going to be in big trouble.
David – New sales guy has a positive attitude, perhaps too optimistic. It worries me a bit. Lot’s of appointments in his first 3 weeks. I have faith though that he’ll come through.
Marketing Company – We’ll spend $42,000 before we see even a drop of results from this company; and realistically it will be June before we start seeing any return on this. Here I have faith too.
Miriam – We hired Miriam to help with sales support. Last week I learned that she is starting to get complacent, just doing the needful, but no more. We could have given her work to Amy in the Philippines for $1,000 / month, but we are spending 4x more to build an office culture and get motivated people.
Tommy – New support guy. I have little faith in him working out. I asked him this week, what he sees himself doing in 6 months. He answered “oh, I don’t really want to look at the support queue; I want to be a coder.” I’m confused as to why he applied for a customer support job. I’m foolishly looking past this big red flag. April 15th is my cutoff date for him to learn the system.
All in all, we are bleeding cash fast. Lot’s of new internal investment — lot’s of uncertainty. I’m hopeful EagleBank will come through with a small loan to buy us an extra 2 months of time.
But more so I’m hopeful that all these 4 investments pay off. They have to for us to make it to next year and beyond.
-
Distance from Christmas
Back in January 2011, around this time of year, we had a pretty shitty set of weeks. Sometime around then, Tim told me, “you know this is normal; this time of year is considered the most depressing [for the western world] — something to do with no daylight and too many days away from Christmas”
The first few weeks of January 2012 sucked; 2013 was not much better. Sales slumping, employees not working out, system failure, and probably a whole slew of personal issues would always compound around then.
Well, I guess nature and science decided 2014 should be no different. This was the week we almost lost everything, again.
Monday – AACRAO server just dies. Fortunately we had backups off site and were able to recover; but the whole day gone.
Tuesday – AWMA launches. The usual post-launch QA ensues but we discover the iMIS portal is coded like a piece of shit. Tuesday and Wednesday gone.
This morning, at the gym with Zack, i was pretty upbeat. We had record traffic to our servers from the AAF competition, and they held strong on Weds Thurs and Friday. I told Zack in between sets, “you know running a business is like running servers in the cloud” — “you can scale up, be a contractor and make money with less redundancy” — or you can scale out “hire low cost workers who all do the same thing with a marginal profit.”
I didn’t realize 4 hours later all hell would break loose.
It started around noon; 185 people on the site, we would get reports of intermittent time-outs. My first thought was — shit — Rackspace is having a connectivity issue, this can take hours to fix. I immediately contacted Rackspace and learned “a node is failing; let’s take it out of rotation”
An hour goes back, traffic shifts between 150 and 190 users per minute; at the high side things are not doing too well; then at the lower side things are fine. I started to suspect that traffic was indeed the culprit.
An hour goes by and we have to interview Tommy. I’m slightly panicked, but composed for the interview. If this works out to be a bad hire it’s because we were not in our right mind during the interview; he was not brain dead so we made him an offer; probably not the best reason to hire someone.
During the interview, traffic surges to 220+ people — site pretty much dead.
Help desk complaints coming through non-stop. It’s like the healthcare website fiasco, except it is on our shoulders. Marc is out sick; I ask Tim/Zack for help to respond to people as I go into crisis mode.
We knew cloudsites would die at some point; but thought since it made it to 185 and held strong, we were in clear territory. Still, I had a backup server ready to go. 8 GB of Ram, 4 vCPUS, I could get it working within 15 minutes.
The thing about server load is that it will perform in constant time, until it is overloaded. Then it responds to no one. It isn’t a gradual slowdown, it is a shutdown — an all or nothing.
I “fail-over” to the backup server and within seconds that server is dead. From cloudsites handling some traffic to an immediate death. 220 people per minute now really pissed.
I fail back to cloudsites, and try again. This time I provision a massive 24 GB server with 12 vCPUs. I also am on the phone with Rackspace as this is going on. They are treating this as a “high traffic incident.”
As they work on their side, I enable the 24 GB server. It lasted about 16 seconds, 4x more than the less powerful server. Probably my lack of knowledge in the emergency, but for the second time, the site was totally down.
I fail back to cloudsites and just pray that traffic drops below the 180 mark. It doesn’t.
Fortunately, cloudsites finds a way to give me 2x the normal resources and the problem is solved.
I’m breathing again, but I just sat at my desk for 9 hours, eating just the fruit from our weekly fruitbox.
I called both Joanne and George, surprisingly both were confident that we were still the right team for them. Of course if this happens again, I don’t think they’ll be singing the same tune.
At 4:30 PM we had our monthly company strategy discussion; I was frazzled; but made it through. I skipped on the monthly happy hour to stay back and lick off my wounds. Zack stayed back with me and we helped tackle the regular hum-drum issues of the day.
At 7, I get a call from Joanne that “we are not going to tell Jim” (CEO of AAF). I was shocked, I told her that it was a 3 hour widespread outage with maybe 1000 people impacted, probably not the best idea to keep it under the cover. I guess we’ll see how that blows over.
Shitty day for sure. Credibility hurt pretty badly, but not irreparably.
What’s next?
Improve infrastructure; test the crap out of the improvements; pray this doesn’t happen again before we are ready.
